
How does your AI model really think?
unpacking AI rationalization and output derivation

Let’s run a quick thought experiment. You ask your AI tool: “What features should we prioritize next quarter?” It gives you a confident, well-structured, surprisingly plausible answer. You screenshot it. You bring it to the roadmap meeting. Maybe you even use some of its phrasing in the deck.
Now: do you actually know what just happened inside that system? Not philosophically, mechanically. Do you know how it arrived at that answer? What was it actually doing when it “thought” about your question?
If the answer is no, and for most PMs it is, then you’re making product decisions with a black box you’ve decided to trust without understanding why you should. That’s worth fixing.
This isn’t a piece about whether AI is good or bad for product management. It’s a framework for understanding the machine. Because once you understand how LLMs actually work, you stop using them wrong.
Step One: Forget Everything You Think “Thinking” Means
The single biggest misconception PMs have about AI models is embedded in the language we use to describe them. We say they “think,” “understand,” “reason,” “know.” These words are catastrophically misleading.
Large language models do not think. They predict. More precisely: given a sequence of tokens (words, parts of words), they calculate the statistically most probable next token, over and over, very fast, across billions of learned patterns from human-generated text.
That’s it. That’s the core mechanism. Everything else, the apparent reasoning, the structured output, the uncanny relevance, is an emergent property of doing that one thing at enormous scale with extraordinary training data.
The model isn’t retrieving an answer from somewhere. It’s constructing one that looks like what an answer should look like.
This distinction matters profoundly for product decisions. When a model gives you a confident recommendation, it’s not because it evaluated your situation and reached a conclusion. It’s because the pattern of your prompt, combined with patterns learned during training, made that response the statistically coherent continuation. Confidence in the output is a stylistic feature, not an epistemic signal.
The Pipeline: What Actually Happens Between Your Prompt and the Answer
To understand where AI output comes from, and where it can go wrong, it helps to visualize the system as a pipeline. Each stage introduces specific opportunities and specific failure modes that directly affect how you should interpret what comes out.
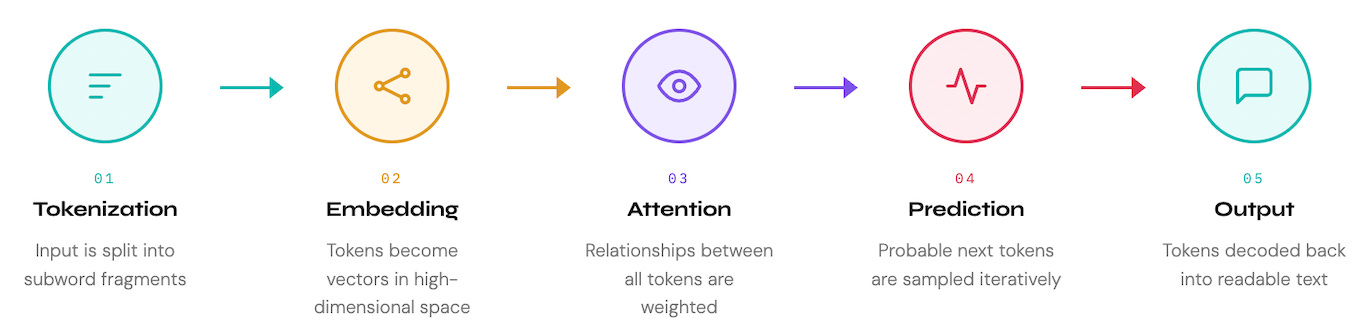
What Does This Mean for Product Decisions?
Once you internalize the pipeline, a clear framework emerges for categorizing what AI is actually good for in a product context, and what it’s constitutionally incapable of doing well.
The key axis isn’t complexity. It’s whether the task requires pattern completion (AI’s native strength) or grounded judgment (a fundamentally human act).
✅ AI-native tasks (Pattern Completion): Based on your ask, AI is completing patterns it has seen billions of times. For eg: summarizing research, drafting PRDs, generating user story variants, formatting data, synthesizing themes from transcripts.
✅ Assisted tasks (Structured Exploration): AI can expand the solution space, but you decide what’s in bounds. For eg: brainstorming frameworks, stress-testing assumptions, generating competing hypotheses.
✅ Human-led tasks (Contextual Judgment): These require organizational context the model fundamentally doesn’t have and can’t have. For eg: prioritization calls, stakeholder trade-offs, timing decisions.
✅ Human-only tasks (Creative Direction): The model predicts plausible next steps. It cannot define what “right” looks like for your specific users, market, and moment.
The Hidden Variable: What the Model Was Trained On
Here’s the dimension most PMs never think about: every response you receive is shaped not just by your prompt, but by the entire corpus of text the model was trained on. The model’s “knowledge” of product management is constructed from every PM blog post, product spec, business book, and LinkedIn thread that made it into training data.
When you ask an AI for product strategy, you’re not getting analysis.
You’re getting the weighted average of everything the internet has ever said about product strategy, filtered through the lens of what a “good answer” looks like to a model fine-tuned on human feedback.
That’s useful. But it’s not the same as thinking.
Three questions to ask before trusting AI output:
Is this pattern completion or judgment? If the AI is summarizing, drafting, or formatting, trust it more. If it’s recommending, prioritizing, or predicting, verify independently.
Does this require context the model doesn’t have? Your org’s specific constraints, your users’ specific behaviors, your market’s specific dynamics. The model doesn’t know these. Any output that depends on them is an educated guess dressed as analysis.
Am I being persuaded by confidence or by evidence? LLMs produce fluent, structured, confident-sounding output regardless of accuracy. The quality of the prose is not a signal about the quality of the reasoning.
The Mental Model That Changes Everything
Stop thinking of your AI tool as a smart colleague who happens to work very fast. Start thinking of it as an extraordinarily well-read intern who has consumed every document ever written about your field, but has never actually shipped a product, talked to a user, or sat in a difficult stakeholder meeting.
That intern is genuinely useful. You’d be foolish not to leverage what they’ve absorbed. But you wouldn’t hand them the roadmap and ask them to run the quarter. You’d use their pattern recognition to accelerate your thinking, then apply your judgment, your context, and your conviction to the actual decision.
That’s the relationship worth building with AI. Not delegation, not distrust. Informed collaboration, where you know exactly what the machine is doing, and you stay firmly in charge of what it cannot.
Hi Esha. I sent you a DM about this post a few days ago. Maybe you missed it.